
Translate this page into:
Optimizing sizing schedules of aircrew helmets using machine learning techniques

*Corresponding author: Dr P Biswal, MBBS, MD (Aerospace Medicine), Head of Department, Department of Human Engineering and Human Factors, Institute of Aerospace Medicine IAF, Vimanapura, Bengaluru - 560 017, Karnataka, India. drpunyashlok@gmail.com
-
Received: ,
Accepted: ,
How to cite this article: Biswal P, Swamy SG. Optimizing sizing schedules of aircrew helmets using machine learning techniques. Indian J Aerosp Med 2020;64(1):18-22.
Abstract
Introduction:
Aircrew equipment assemblies are life critical equipment worn by the aircrew to ensure protection from various life-threatening environmental conditions that may occur in nominal or off-nominal flight conditions. It is important for the sizing system of body worn aircrew equipment to be divided into different size classes such that it is as representative of existing groups in the population as feasible. Machine learning techniques provide a powerful tool to develop efficient sizing systems that are representative of actual body types existing in the population. The objective of the study was to use machine learning clustering techniques to identify naturally existing body types to formulate an optimal sizing system for an aircrew helmet.
Material and Methods:
The standard sizing schedule of an aircrew helmet using head length and head breadth was studied. An iterative semi-supervised machine learning protocol called K-means clustering was used to identify naturally occurring clusters of head types within the population. The cluster boundaries were identified to develop the final sizing schedule. Analysis of variance (ANOVA) with post hoc analysis was carried out on the four head lengths and head breadths.
Results:
Four clusters of head type were identified using K-means clustering. This led to a sizing schedule which can be descriptively called “Short-Narrow,” “Short-Broad,” “Long-Narrow,” “Long-Broad.” ANOVA showed a statistically significant difference between the four clusters for both head length and head breadth.
Conclusion:
Consideration of several variables in sizing schedules often fails to meet desired fitment. Standard sizing methods use linear partitions on individual control parameters. In reality, the proportional variation between parameters is not linear. Machine learning tools help in identification of naturally occurring clusters within the database considering several variables at the same time. This study uses machine learning techniques to identify existing groups in a population and develop a final sizing schedule. Similar analysis for other aircrew equipment assemblies can be carried out to determine sizing schedules which assist in design and fitment.
Keywords
Sizing schedule
Machine learning
Cluster analysis
Aircrew helmet

INTRODUCTION
The abnormal environment of flight requires aircrew to wear various equipment which either help him to maintain physiological function, assist in mission accomplishment, or provide protection in case of an emergency. Due to the critical nature of these aircrew equipment assemblies, great care needs to be undertaken to ensure proper fitment so that their function is not compromised.
Proper fitment of aircrew equipment assembly involves analysis of human body characteristics (i.e., size and shape), assessment of human-equipment interfaces, accurate determination of sizing schedules, and effective selection of equipment size for the aircrew. Although customized fitment of equipment would provide the best fit, the logistics of carrying this out on a large scale are uneconomical and difficult to implement.
The aim of this study was to use machine learning protocols for the identification of naturally occurring groups of anthropometric head types in the IAF aircrew. This study also proposes a sizing schedule for an aircrew helmet based on this analysis.
Challenges in sizing
A sizing system classifies a specific population into homogeneous subgroups based on some key body dimensions of body shape characteristics, and they share the same garment size.[1] Conventionally, designers have identified a set of key body dimensions and linearly divided them into sets varying from small to large. A linear division of a parameter only works if the relationships between the critical parameters required for sizing are linear. Joshi et al. in their study of a prototype aircrew helmet showed that for a helmet that utilized head length and head breadth as sizing parameters, the overall fitment was poor due to a linear sizing schedule.[2] It would thus be understandable that standard statistical measures of percentile, which are graded from small to large, are inadequate to capture the diversity of the human body.
Data mining for group identification
In recent years, with the availability of large volumes of data, data mining has been employed in various industries using various machine learning techniques. This allows researchers to sift through huge amounts of data and classify them into groups which may make sense to the human observer. One important method of data mining is called cluster analysis, which classifies or partitions the data set into subsets (clusters) so that the data in each subset share some common traits.[3-6] The use of data mining techniques in clothing industry has been reviewed in an article by Elawad et al.[7]
MATERIAL AND METHODS
The study used head length and head breadth (head width) measurements of 834 aircrew subjects. The head length and head breadth were measured using a standard commercially available caliper with a least count of 1 mm. The head length was defined as “maximum length of the head from glabella to occiput.” The head breadth was defined as “maximum breadth of the head at the most lateral projection.” These data have been summarized in the IAF Anthropometry Survey 2013.
Semi-supervised machine learning is an iterative procedure and therefore steps have been repeated to achieve an optimal solution. This study used one of the most widely used machine learning called the K-means method.[3] All the iterations have not been presented in the results for reasons of brevity and clarity and only the final solution is discussed. Outliers were identified in two ways: First, by examining the minimums and maximums for each variable, and second and more importantly, through Mahalanobis distance in multivariate space.[8,9] While outliers were not omitted from descriptive statistics, they were excluded from final K-means clustering.
Practical considerations of minimizing the number of sizes and, accommodating the maximum number of subjects were included in decisions. The percentage of the sample accommodated in each size was calculated. Body dimensions, not helmet dimensions, were reported for size solutions. Analysis of variance (ANOVA) with post hoc analysis was done on the clusters to verify if statistically significant differences existed between the clusters.
The Mahalanobis outlier’s identification and ANOVA were done using the SPSS version 23. The K-means cluster analysis was carried out using Orange version 3.22.0 which is an open-source machine learning and data visualization software.[10]
RESULTS
Eight hundred and thirty-four male aircrew data on head length and head breadth were used for the study. The mean range for age was 28.3 years (standard deviation [SD] 5.3 years, 20–45 years). The mean head length was 18.7 cm (SD = 0.9 cm, range = 12.9–21.1 cm). The mean head breadth was 14.89 cm (SD = 0.8 cm, range = 10.1–20.1 cm). The distribution of head length and head breadth is shown in Figure 1a and b.
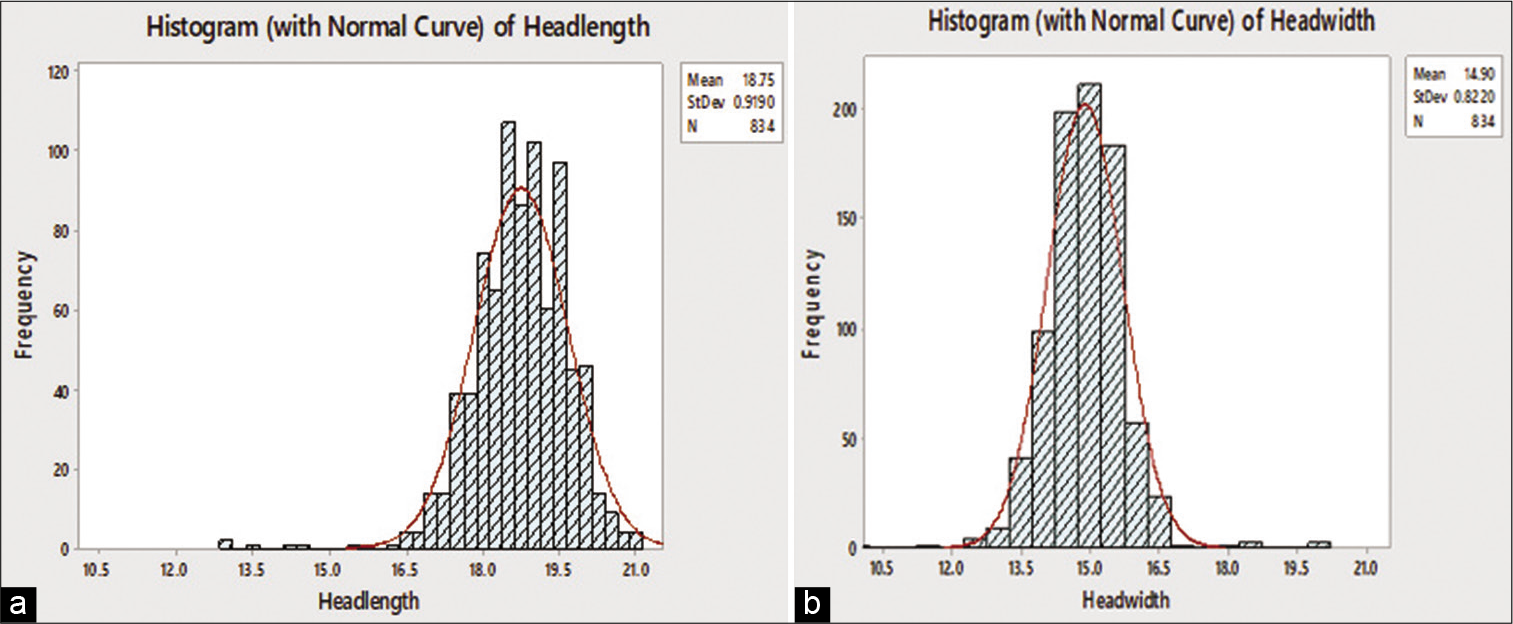
- (a) Distribution of head length. (b) Distribution of head breadth.
The Mahalanobis distance of the combination of head length and head breadth was calculated. Seventeen individuals (2.03% out of 834) with a Chi-square value <0.003 were identified as outliers and their data were not used for further computation.
The head length and head breadth data of remaining 817 individuals were subjected to a semi-supervised machine learning protocol called K-means analysis and it was found that the four cluster solution was the most optimal.[11] A repeat iteration of the Mahalanobis distance was calculated within each cluster and additional 17 individuals (2.08% out of 817) were identified as outliers in all the four clusters. Thus, a final number of 800 individuals (95.9% out of 834) were divided into four clusters. The distribution is shown in Table 1. A scatter plot of the distribution is depicted in Figure 2.
| Cluster | Total | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||
| Head length | 19.5 | 17.9 | 19.3 | 18.3 | |
| Head breadth | 14.5 | 15.4 | 15.4 | 14.3 | |
| Number of cases | 186 | 172 | 218 | 224 | 800 |
| Percentage of cases | 23.25 | 21.5 | 27.25 | 28 | 100 |
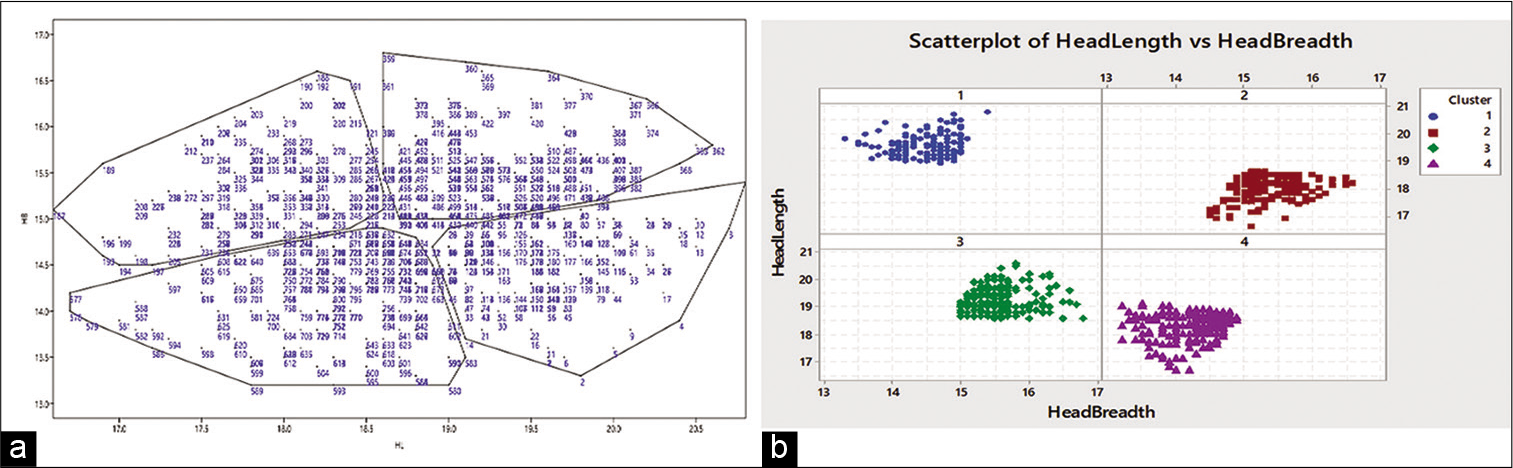
- (a) Head length and head breadth in the four clusters. (b) Distribution of head length and head breadth in the four clusters.
From Figure 2, the four clusters can be seen to be describing the following four types of heads:
Cluster 1: Long narrow
Cluster 2: Short broad
Cluster 3: Long broad
Cluster 4: Short narrow
ANOVA showed that there was a statistically significant difference in the head lengths among the four clusters [F (3, 796) = 564.707, P < 0.001]. A statistically significant difference was also found in the head breadths among the four clusters [F (3, 796) = 490.475, P < 0.001]. Post hoc analysis showed statistically significant differences between each pair of the four clusters for head length and head breadth.
DISCUSSION
The designer perspective on the equipment assembly has always focussed on the functional capability of the system. In the case of an aircrew helmet, aspects of injury protection, injury potential during ejection, visor characteristics, etc., take priority. The aspect of sizing is often the last to be addressed. In case of specialized equipment such as aircrew helmets, aircrew oxygen masks, and anti-G suits, the user population within a country is often quite restricted. In such a situation, customization would be an ideal approach to fitment. This can be realized if the population is not too large and the facilities for customization are available with reasonable ease, commensurate with the life cycle of the equipment.
However, when the user population is large, it becomes uneconomical to customize for all. This requires the use of sizing schedules such that different dimensions of the equipment are available for use by different sized individuals. However, keeping the manufacturing economics and stocking logistics in mind, it is also essential to make as few sizes as possible, yet fitting a large population as feasible.
Study population
This study was carried out on the data of fighter pilots, as they operate in high G environments, where snug fit of the helmet is considered essential. The present study does not include female fighter pilots due to the low numbers as on date. The long-term implications of this study in aircrew helmets are evident as the dimensions of the adult head do not change appreciably with age due to fat or muscle deposition as would be the case with other body dimensions. Therefore, the sizing schedule once made is unlikely to change over the career of an individual aircrew. The sizing schedules are also unlikely to show change in secular trends over the next four to five decades at the least.
Detecting outliers
There are very few equipment which may be designed with only one control anthropometric dimension. Most would use multiple anthropometric parameters, with the aircrew helmet being one of the simplest and the anti-G suit being an example of the more complex ones. Identification of outliers is useful, as accommodating unusual body sizes or proportions can be done by customization without affecting simpler sizing schedules for the majority of the population. The Mahalanobis distance is used to detect outliers in multivariate normal data. It measures how far away an observation is from the center of a sample while accounting for correlations in the data. It is better than looking at the univariate Z-scores of each coordinate because a multivariate outlier does not necessarily have extreme coordinate values.[8,12,13] This is represented graphically in Figure 3.
![Mahalanobis distance in multivariate space. Courtesy reference.[13]](/content/110/2020/64/1/img/IJAM-64-018-g003.png)
- Mahalanobis distance in multivariate space. Courtesy reference.[13]
In this study, the outliers’ detection was done in two steps. In the first step, outliers from the entire data were identified. In the second step, the outliers within each cluster were identified. After removing the outliers, 95.9% of the data was considered for the final sizing schedule. Considering the traditional practice of fitting 3rd to 97th percentile of a population, the fitment in this study may be considered adequate.
Cluster analysis
Clustering is the classification or partitioning of a data set into subsets (clusters) so that the data in each subset share some common trait. One of the commonly used methods is the K-means method. In this case, the initial clusters and the number of clusters are randomly chosen. The observations are reassigned by moving them to the cluster whose centroid is closest to that observation. Reassignment continues until every observation is appointed to the cluster with the closest centroid. This machine learning protocol uses iterative methods to improve the cluster formation in each step until there is no further improvement possible.[3,6,7] In this study, the initial cluster numbers were randomly set between 2 and 10. The machine learning protocol prepared solutions with 2–10 clusters in the same data.
The optimal number of clusters was identified using silhouette coefficient analysis. Silhouette analysis is used to study the separation distance between the resulting clusters. The silhouette plot displays a measure of how close each point in one cluster is to points in the neighboring clusters and thus provides a way to assess parameters like number of clusters visually.[11] This method of use of a combination of machine learning with human intervention can be considered as an example of semi-supervised machine learning. In this study, the solution with four clusters was found to be optimal from the silhouette scores. On visual assessment, such a classification has a high face validity in terms of the descriptors that can be applied to these four clusters, namely, Cluster-1: Long narrow, Cluster-2: Short broad, Cluster-3: Long broad, and Cluster-4: Short narrow.
ANOVA was done between the clusters for both the parameters of head length and head breadth. The statistically significant effect of clustering on the means (centroids) of the clusters demonstrates that these clusters that have been identified belong to different groups.
Cluster analysis from the designer perspective
The clusters identified by the machine learning techniques bring out naturally occurring groups within the population which have some commonality when all the control anthropometric parameters are considered together. These naturally occurring groups are not evident when individual parameters are considered in isolation. In this study, two parameters of head length and head breadth have been traditionally used to design aircrew helmets. However, using each of the parameters separately and using linear sizing techniques have resulted in poor fitment.[2] The head types identified by the cluster analysis closely follow the proportional variation that exists in nature. Trying to design across these groups/head types would result in poor fitment. The designer can use these cluster boundaries to identify the sizing schedule for designing the equipment.[1,3,4,7,14] Within the clusters, the intercluster variation would have to be addressed by provisions of adjustability. In this study, the use of liners within the helmet to ensure snug fit is advocated. The sizing of liner thickness has been discussed in an article by Joshi et al.[2]
Cluster analysis from the user perspective
The user requires a proper sizing schedule for good fitment and proper stocking. The clusters which are taken from the actual population ensure that each person fits into one cluster or the other. The measurement of the head length and head breadth can be taken early in the career and the appropriate size advocated. It is unlikely that measurements of head length or head breadth would change for an individual during his lifetime. Individuals not included in the population for this particular study are likely to still fit into one of the four clusters as the sample size of 834 for two parameters is considered sufficiently large for representing the head sizes of the Indian fighter aircrew population.
The proportions of the population which fit into the various clusters are given in Table 1. Stocking of aircrew helmets in those proportions is likely to be helpful in providing the requisite sizes at any air base.
SUMMARY
A study was conducted on 834 aircrew data with an aim to use machine learning techniques for identifying four types of head shapes existing in the population. These cluster boundaries can be used to design aircrew helmets for a better fit. The clusters can also be used to prepare sizing schedules which ensure snug fit for aircrew head types/shapes. The proportions of these clusters can be used for demand and stocking for logistic purposes.
CONCLUSION
Linear division of multiple anthropometric parameters to determine sizing schedules leads to poor fit due to proportional variation between the parameters. This study has been carried out on an aircrew equipment which had two critical control parameters. The technique is even more useful in case of equipment which use multiple parameters. Apart from the skeletal structure differences by gender of individuals, proportional variations are also introduced into a population with age and gender due to adipose tissue deposition. This wide variation due to body types, age, gender, and ethnic differences is a challenge for designers. Machine learning techniques provide a powerful tool for identifying these naturally occurring groups, as human beings find it difficult to deal with multivariate spaces beyond three dimensions. Similar analysis for other aircrew equipment assemblies can be carried out to determine sizing schedules which assist in design and fitment.
Declaration of patient consent
Participant’s consent not required as participant’s identity is not disclosed or compromised.
Financial support and sponsorship
Nil.
Conflicts of interest
There are no conflicts of interest.
References
- The development of sizing systems for Taiwanese elementary-and high-school students. Int J Ind Ergon. 2007;37:707-16.
- [CrossRef] [Google Scholar]
- Sizing trials of a prototype aircrew helmet : Lessons re-learnt. Ind J Aerosp Med. 2009;53:44-52.
- [Google Scholar]
- Developing female size charts for facilitating garment production by using data mining. J Chin Inst Ind Eng. 2007;24:245-51.
- [CrossRef] [Google Scholar]
- Mining the shirt sizes for Indian men by clustered classification. Int J Info Technol Comp Sci. 2012;6:12-7.
- [CrossRef] [Google Scholar]
- A Comparative Study on Application of Data Mining Technique in Human Shape Clustering: Principal Component Analysis vs. Factor Analysis, Taiwan. 5th IEEE Conference on Industrial Electronics and Applications; 2010-2014.
- [Google Scholar]
- Using Cluster Analysis to Define Geographical Rating Territories In: Discussion Paper Program. United States: Casualty Actuarial Society; 2008. p. :34-52.
- [Google Scholar]
- Application of data mining methods in establishing sizing system for clothing industry. Int J Eng Sci Res Technol. 2015;4:32-9.
- [Google Scholar]
- Development of sizing systems for protective clothing for the adult male. Ergonomics. 1999;42:1249-57.
- [CrossRef] [PubMed] [Google Scholar]
- Orange: Data mining fruitful and fun-a historical perspective. Informatica. 2013;37:55-60.
- [Google Scholar]
- Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math. 1987;20:53-65.
- [CrossRef] [Google Scholar]
- The Geometry of Multivariate Versus Univariate Outliers-The DO Loop. Available from: https://www.blogs.sas.com/content/iml/2019/03/25/geometry-multivariate-univariate-outliers.html [Last accessed on 2019 Sep 08]
- [Google Scholar]
- An optimisation approach to apparel sizing. J Oper Res Soc. 1998;49:492-9.
- [CrossRef] [Google Scholar]




